
S-SONDO
Self-Supervised Knowledge Distillation for General Audio Foundation Models
ICASSP 2026
Authors: Mohammed Ali El Adlouni*, Aurian Quelennec*, Pierre Chouteau, Geoffroy Peeters, Slim Essid
LTCI, Telecom Paris, Institut Polytechnique de Paris
S-SONDO distills large audio foundation models into lightweight students that are up to 61x smaller while retaining up to 96% of teacher performance — using only output embeddings, no logits or layer-level alignment required.
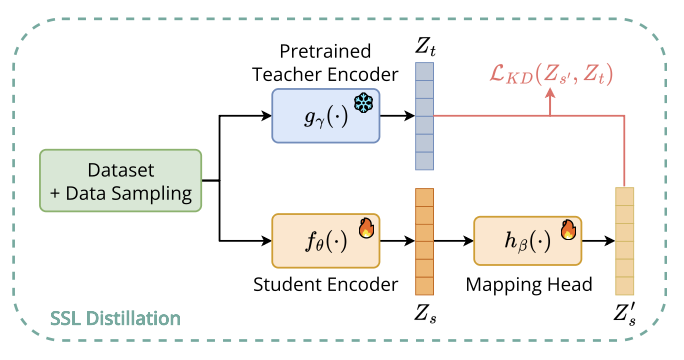
Overview of the S-SONDO framework. Student embeddings are mapped and aligned with teacher embeddings in the teacher's latent space through self-supervised knowledge distillation.
Install
pip install ssondo
Quick Start
from ssondo import get_ssondo
# Load model (auto-downloads and caches)
model = get_ssondo()
# Extract embeddings from raw audio (mono, 32kHz)
embeddings = model(audio) # (batch, n_segments, 960)
That's it. No preprocessing, no config files, no manual downloads.
Pretrained Classifiers
7 ready-to-use classifiers, trained via linear probing on standard audio benchmarks:
model = get_ssondo(head="esc50")
logits = model(audio) # (batch, 50) — environmental sound classification
| Head | Task | Classes |
|---|---|---|
esc50 |
Environmental sound classification | 50 |
us8k |
Urban sound classification | 10 |
fsd50k |
Sound event detection | 200 |
gtzan |
Music genre classification | 10 |
openmic |
Instrument recognition | 20 |
nsynth |
Instrument family classification | 11 |
magna-tag-a-tune |
Music auto-tagging | 50 |
from ssondo import list_heads
print(list_heads()) # see all available heads
Custom Classification Heads
Attach your own head for any downstream task:
# Linear head
model = get_ssondo(head="linear", n_classes=10)
# MLP with custom hidden layers
model = get_ssondo(head="mlp", n_classes=10, hidden_sizes=[512, 256])
# Freeze backbone for linear probing
model.freeze_backbone()
model.train()
logits = model(audio)
loss = criterion(logits, labels)
loss.backward() # only head parameters are updated
Results
Downstream evaluation across 7 audio tasks (4 music + 3 environmental sound). Students retain up to 96.4% of teacher performance while being up to 61x smaller.

| w/ BDS | wo/ BDS | |
|---|---|---|
| MATPAC++ → MobileNetV3 | 73.0 | 72.7 |
| MATPAC++ → DyMN | 72.6 | 72.9 |
| MATPAC++ → ERes2Net | 70.8 | 44.8 |
| M2D → MobileNetV3 | 69.2 | 69.4 |
| M2D → DyMN | 68.7 | 69.2 |
| M2D → ERes2Net | 69.2 | 68.7 |
Impact of Balanced Data Sampling (BDS) on downstream performance. BDS is critical for ERes2Net, improving from 44.8 to 70.8 average accuracy.
Available Checkpoints
from ssondo import list_models
print(list_models()) # see all available backbones
| Model | Teacher | Student | Params | Emb. Size |
|---|---|---|---|---|
matpac-mobilenetv3 |
MATPAC++ | MobileNetV3 | 2.9M | 960 |
matpac-dymn |
MATPAC++ | DyMN | 8.7M | 960 |
matpac-eres2net |
MATPAC++ | ERes2Net | 1.4M | 10240 |
m2d-mobilenetv3 |
M2D | MobileNetV3 | 2.9M | 960 |
m2d-dymn |
M2D | DyMN | 8.7M | 960 |
m2d-eres2net |
M2D | ERes2Net | 1.4M | 10240 |
API Reference
from ssondo import get_ssondo
# Embeddings only (default)
model = get_ssondo()
embeddings = model(audio) # (batch, n_segments, 960)
emb = model.get_embeddings(audio) # (batch, 960) — mean-pooled
# Pretrained classifier
model = get_ssondo(head="esc50")
logits = model(audio) # (batch, 50)
# Custom head
model = get_ssondo(head="linear", n_classes=10)
model = get_ssondo(head="mlp", n_classes=10, hidden_sizes=[512, 256])
# Finetuning
model.freeze_backbone() # linear probing
model.unfreeze_backbone() # full finetuning
# GPU
model = get_ssondo(device="cuda")
# Local checkpoint
model = get_ssondo("path/to/checkpoint.ckpt")
# Properties
model.embedding_dim # 960
model.backbone # raw nn.Module
Input Requirements
| Parameter | Value |
|---|---|
| Format | Raw mono waveform |
| Sample rate | 32,000 Hz |
| Window | 10s segments (automatic) |
| Spectrogram | 128 mel bands, 50–16000 Hz |
Training Code
Full 4-step training pipeline to reproduce all results:
git clone https://github.com/MedAliAdlouni/ssondo_temp
cd ssondo_temp/training_ssondo
./setup.sh # install deps, download models
./run_pipeline.sh # end-to-end demo
See the training README for details.
Citation
@inproceedings{eladlouni2026ssondo,
title={S-SONDO: Self-Supervised Knowledge Distillation for General Audio Foundation Models},
author={El Adlouni, Mohammed Ali and Quelennec, Aurian and Chouteau, Pierre and Peeters, Geoffroy and Essid, Slim},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year={2026}
}
License
MIT