|
|
--- |
|
|
base_model: |
|
|
- Qwen/Qwen-Image |
|
|
pipeline_tag: text-to-image |
|
|
library_name: diffusers |
|
|
license: apache-2.0 |
|
|
--- |
|
|
|
|
|
<h1 align="center">TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows</h1> |
|
|
|
|
|
<div align="center"> |
|
|
|
|
|
[](https://zhenglin-cheng.com/twinflow)  |
|
|
[](https://huggingface.co/inclusionAI/TwinFlow)  |
|
|
[](https://github.com/inclusionAI/TwinFlow)  |
|
|
<a href="https://arxiv.org/abs/2512.05150" target="_blank"><img src="https://img.shields.io/badge/Paper-b5212f.svg?logo=arxiv" height="21px"></a> |
|
|
|
|
|
|
|
|
</div> |
|
|
|
|
|
## News |
|
|
|
|
|
- We release **TwinFlow-Qwen-Image-v1.0**! And we are also working on **Z-Image-Turbo to make it more faster**! |
|
|
|
|
|
## TwinFlow |
|
|
|
|
|
Checkout 2-NFE visualization of TwinFlow-Qwen-Image 👇 |
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
### Overview |
|
|
|
|
|
We introduce TwinFlow, a framework that realizes high-quality 1-step and few-step generation without the pipeline bloat. |
|
|
|
|
|
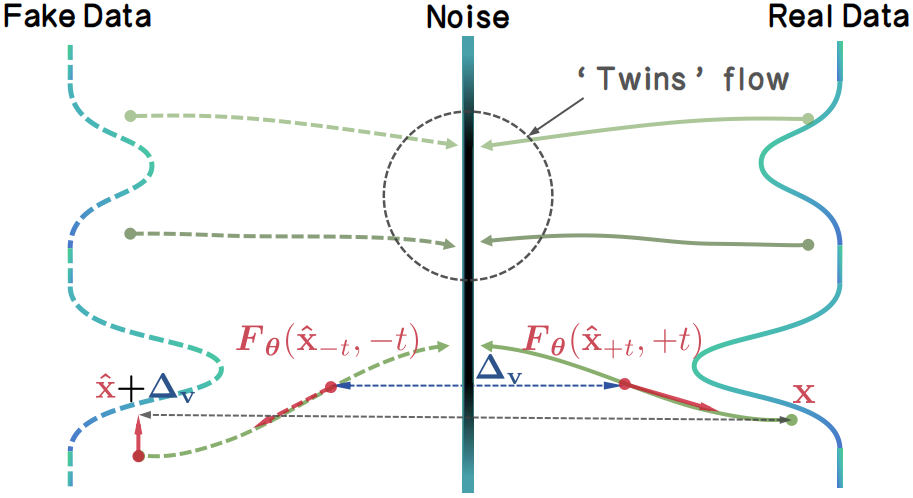
Instead of relying on external discriminators or frozen teachers, TwinFlow creates an internal "twin trajectory". By extending the time interval to $t\in[−1,1]$, we utilize the negative time branch to map noise to "fake" data, creating a self-adversarial signal directly within the model. |
|
|
|
|
|
Then, the model can rectify itself by minimizing the difference of the velocity fields between real trajectory and fake trajectory, i.e. the $\Delta_\mathrm{v}$. The rectification performs distribution matching as velocity matching, which gradually transforms the model into a 1-step/few-step generator. |
|
|
|
|
|
 |
|
|
|
|
|
Key Advantages: |
|
|
- **One-model Simplicity.** We eliminate the need for any auxiliary networks. The model learns to rectify its own flow field, acting as the generator, fake/real score. No extra GPU memory is wasted on frozen teachers or discriminators during training. |
|
|
- **Scalability on Large Models.** TwinFlow is **easy to scale on 20B full-parameter training** due to the one-model simplicity. In contrast, methods like VSD, SiD, and DMD/DMD2 require maintaining three separate models for distillation, which not only significantly increases memory consumption—often leading OOM, but also introduces substantial complexity when scaling to large-scale training regimes. |
|
|
|
|
|
### Inference Demo |
|
|
|
|
|
Install the latest diffusers: |
|
|
|
|
|
```bash |
|
|
pip install git+https://github.com/huggingface/diffusers |
|
|
``` |
|
|
|
|
|
Run inference demo `inference.py`: |
|
|
|
|
|
```python |
|
|
python inference.py |
|
|
``` |
|
|
|
|
|
## Citation |
|
|
|
|
|
```bibtex |
|
|
@article{cheng2025twinflow, |
|
|
title={TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows}, |
|
|
author={Cheng, Zhenglin and Sun, Peng and Li, Jianguo and Lin, Tao}, |
|
|
journal={arXiv preprint arXiv:2512.05150}, |
|
|
year={2025} |
|
|
} |
|
|
``` |
|
|
|
|
|
## Acknowledgement |
|
|
|
|
|
TwinFlow is built upon [RCGM](https://github.com/LINs-lab/RCGM) and [UCGM](https://github.com/LINs-lab/UCGM), with much support from [InclusionAI](https://github.com/inclusionAI). |

