
Whisper Large v3 Turbo (Romanian)
Whisper is an automatic speech recognition (ASR) system developed by OpenAI. It can transcribe and translate spoken language into text with high accuracy, supporting multiple languages, accents, and noisy environments. It is designed for general-purpose speech processing and can handle various audio inputs.
Whisper-large-v3-turbo is an optimized version of OpenAI's Whisper-large-v3 model, designed to enhance transcription speed while maintaining high accuracy. This optimization is achieved by reducing the number of decoder layers from 32 to 4, resulting in a model that is significantly faster with only a minor decrease in transcription quality.
 More details
More details
Fine-tune
Under the guidance of project manager Ionuț Vișan, we have successfully fine-tuned the Whisper-large-v3-turbo model on the Common Voices Corpus 20 (Romanian) dataset, consisting of 41,431 audio files (approximately 47 hours), each accompanied by its corresponding text transcription.
Before fine-tuning our model with the dataset, we assessed the word error rate (WER) and character error rate (CER) on the test set (test_common_voices20.csv) using the pre-trained openai/whisper-large-v3-turbo model to establish baseline performance.
Base performance:
- WER: 20.72%
- CER: 6.50%
Configuration
- Trainable layers = all (encoder = 32, decoder = 4)
- Learning rate = 4e-6
- Batch size = 2 (for both dataloaders)
- Gradient accumulation steps = 8
- Optimizer = AdamW
- Weight decay = 0.2
- Epochs = 20
- Scheduler = Linear (with warmup = 0.1)
Dropout:
- Encoder =
- 0.2 if idx == 20 else
- 0.1 if idx in [21, 22, 29, 30] else 0.0
- Decoder =
- 0.2 if idx == 1 else 0.1
- 0.2 if idx == 20 else
- 0.1 if idx in [21, 22, 29, 30] else 0.0
- 0.2 if idx == 1 else 0.1
The condition for saving the model is that the test loss, Word Error Rate (WER), and Character Error Rate (CER) must be lower than the previously recorded best values.
Results
The fine-tuning process took 6,360 minutes (106 hours) on a single NVIDIA RTX 4500 Ada Generation GPU.
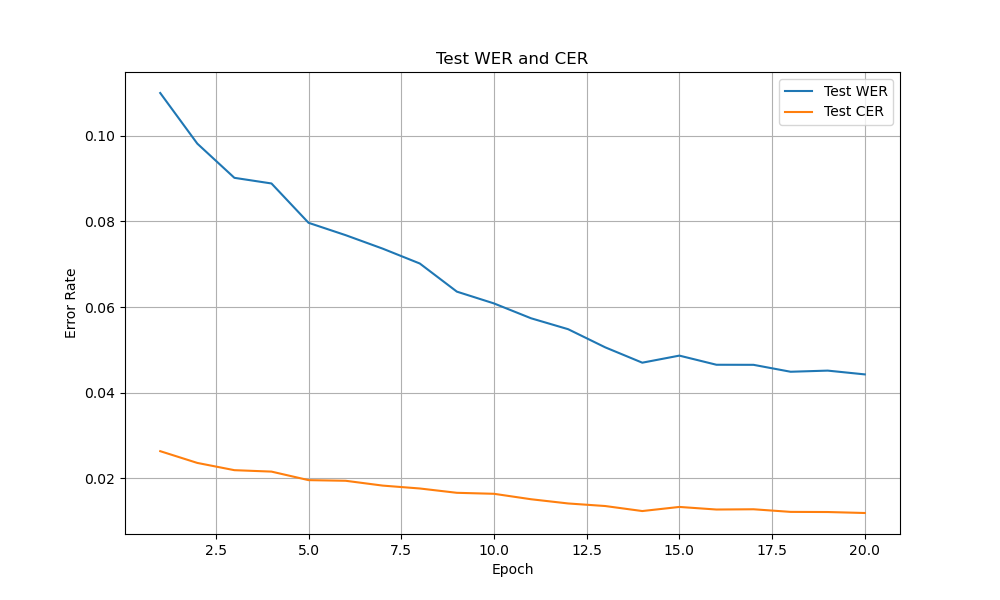
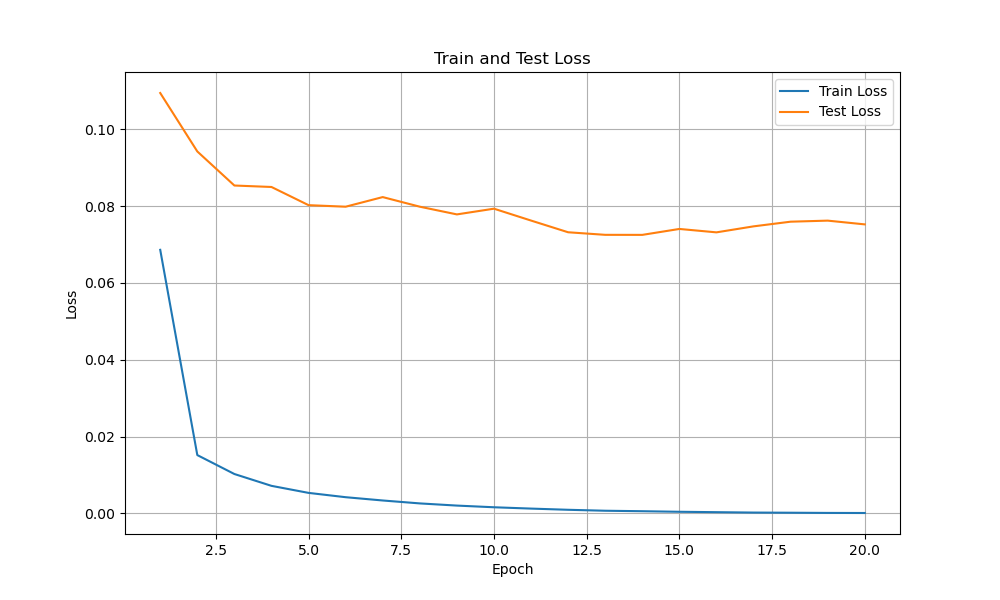


The fine-tuned model was saved at epoch 14 with new:
- WER: 4.69%
- CER: 1.22%
How to use
1. If you want to transcribe a mono-channel audio file (.wav) containing a single speaker, use the following code:
Click to expand the code
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import torchaudio
import torch
model_name = "TransferRapid/whisper-large-v3-turbo_ro"
# Load processor and model
processor = WhisperProcessor.from_pretrained(model_name)
model = WhisperForConditionalGeneration.from_pretrained(model_name)
# Move model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def preprocess_audio(audio_path, processor):
"""Preprocess audio: load, resample if needed, and convert to model input format."""
waveform, sample_rate = torchaudio.load(audio_path)
# Resample to 16kHz if needed
if sample_rate != 16000:
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)
waveform = resampler(waveform)
# Process audio into model input format
inputs = processor(waveform.squeeze().numpy(), sampling_rate=16000, return_tensors="pt")
# Move inputs to device
inputs = {key: val.to(device) for key, val in inputs.items()}
return inputs
def transcribe(audio_path, model, processor, language="romanian", task="transcribe"):
"""Generate transcription for an audio file."""
inputs = preprocess_audio(audio_path, processor)
forced_decoder_ids = processor.tokenizer.get_decoder_prompt_ids(language=language, task=task)
with torch.no_grad():
generated_ids = model.generate(inputs["input_features"], forced_decoder_ids=forced_decoder_ids)
transcription = processor.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
return transcription[0]
# Define audio path
audio_file = "audio.wav"
# Run transcription
transcription = transcribe(audio_file, model, processor)
print("Transcription:", transcription)
Example of result:
Transcript: Astăzi am avut o zi superbă.
2. If you want to transcribe a stereo audio file (.wav or .mp3) containing a conversation between two speakers, use the following code:
Click to expand the code
import os
import torchaudio
import numpy as np
import librosa
import webrtcvad
import soundfile as sf
from pydub import AudioSegment
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import torch
# Load model from Hugging Face
model_name = "TransferRapid/whisper-large-v3-turbo_ro"
processor = WhisperProcessor.from_pretrained(model_name)
model = WhisperForConditionalGeneration.from_pretrained(model_name)
# Move model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def convert_mp3_to_wav(mp3_file_path):
"""Convert MP3 to WAV (16kHz)."""
audio = AudioSegment.from_mp3(mp3_file_path)
wav_16k_file_path = mp3_file_path.replace(".mp3", "_16k.wav")
audio.set_frame_rate(16000).export(wav_16k_file_path, format="wav")
return wav_16k_file_path
def extract_audio_channels(wav_file_path):
"""Extract left and right channels from stereo WAV."""
y, sr = librosa.load(wav_file_path, sr=None, mono=False)
if len(y.shape) == 1:
mono_file = wav_file_path.replace(".wav", "_mono.wav")
sf.write(mono_file, y, sr)
return y, None, sr, mono_file, None
left_channel, right_channel = y[0], y[1]
left_file = wav_file_path.replace(".wav", "_left.wav")
right_file = wav_file_path.replace(".wav", "_right.wav")
sf.write(left_file, left_channel, sr)
sf.write(right_file, right_channel, sr)
return left_channel, right_channel, sr, left_file, right_file
def detect_speech_intervals(channel_data, sr, vad_level=3):
"""Detect speech activity using VAD (30ms frames)."""
vad = webrtcvad.Vad(vad_level)
frame_duration = 30
frame_length = int(sr * frame_duration / 1000)
frames = librosa.util.frame(channel_data, frame_length=frame_length, hop_length=frame_length)
speech_intervals = []
for i, frame in enumerate(frames.T):
pcm_data = (frame * np.iinfo(np.int16).max).astype(np.int16).tobytes()
if vad.is_speech(pcm_data, sr):
start_time, end_time = (i * frame_duration) / 1000, ((i + 1) * frame_duration) / 1000
speech_intervals.append((start_time, end_time))
return speech_intervals
def merge_intervals(intervals, merge_threshold=1):
"""Merge speech intervals with a gap smaller than merge_threshold."""
if not intervals:
return []
merged = [list(intervals[0])]
for start, end in intervals[1:]:
if (start - merged[-1][1]) <= merge_threshold:
merged[-1][1] = end
else:
merged.append([start, end])
return merged
def save_segments(channel_data, sr, intervals, output_dir="segments", prefix="segment"):
"""Save detected speech segments."""
os.makedirs(output_dir, exist_ok=True)
segment_paths = []
for idx, (start, end) in enumerate(intervals):
start_sample = int(start * sr)
end_sample = int(end * sr)
segment = channel_data[start_sample:end_sample]
segment_path = os.path.join(output_dir, f"{prefix}_{idx+1}.wav")
sf.write(segment_path, segment, sr)
segment_paths.append((start, end, segment_path, prefix))
return segment_paths
def preprocess_audio(audio_path, processor, device):
"""Preprocess audio: load, resample if needed, and convert to model input format."""
waveform, sample_rate = torchaudio.load(audio_path)
if sample_rate != 16000:
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)
waveform = resampler(waveform)
inputs = processor(waveform.squeeze().numpy(), sampling_rate=16000, return_tensors="pt")
inputs = {key: val.to(device) for key, val in inputs.items()}
return inputs
def transcribe(audio_path, model, processor, device, language="romanian", task="transcribe"):
"""Generate transcription for an audio file."""
inputs = preprocess_audio(audio_path, processor, device)
forced_decoder_ids = processor.tokenizer.get_decoder_prompt_ids(language=language, task=task)
with torch.no_grad():
generated_ids = model.generate(inputs["input_features"], forced_decoder_ids=forced_decoder_ids)
transcription = processor.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
return transcription[0]
# Load audio file (MP3 or WAV)
audio_file = "audio.mp3"
# Convert MP3 to WAV if needed
if audio_file.endswith(".mp3"):
wav_file = convert_mp3_to_wav(audio_file)
else:
wav_file = audio_file
# Process stereo or mono file
left_channel, right_channel, sr, left_file, right_file = extract_audio_channels(wav_file)
# Process left channel (or mono)
if left_channel is not None:
left_intervals = detect_speech_intervals(left_channel, sr)
merged_left_intervals = merge_intervals(left_intervals)
left_segments = save_segments(left_channel, sr, merged_left_intervals, output_dir="left_segments", prefix="Left")
else:
left_segments = []
# Process right channel (if stereo)
if right_channel is not None:
right_intervals = detect_speech_intervals(right_channel, sr)
merged_right_intervals = merge_intervals(right_intervals)
right_segments = save_segments(right_channel, sr, merged_right_intervals, output_dir="right_segments", prefix="Right")
else:
right_segments = []
# Combine all segments and sort by start time
all_segments = left_segments + right_segments
all_segments.sort(key=lambda x: x[0])
# Transcribe each segment
for idx, (start, end, segment_path, channel) in enumerate(all_segments, start=1):
transcription = transcribe(segment_path, model, processor, device)
print(f"{idx}. {start:.2f}s → {end:.2f}s | {channel}: {transcription}")
Example of result:
1. 0.00s → 1.12s | Right: Bună ziua, Andreea este numele meu, cu ce vă pot ajuta?
2. 1.43s → 2.54s | Left: Bună ziua doamna Andreea, Antonia mă numesc.
3. 2.72s → 3.08s | Right: Bună Antonia.
4. 3.41s → 5.75s | Left: Voiam doar să vă urez o zi frumoasă.
5. 5.92s → 6.78s | Right: Ah, sunteți o scumpă.
6. 6.94s → 7.81s | Left: Zi superbă, la revedere.
7. 7.89s → 8.55s | Right: La fel, la revedere.
Usage
The model can be used for:
- Advanced voice assistants
- Automatic transcription
- Live subtitling systems
- Voice recognition for call centers
- Voice commands for smart devices
- Voice analysis for security (biometric authentication)
- Dictation systems for writers and professionals
- Assistive technology for people with disabilities
Communication
For any questions regarding this model or to explore collaborations on ambitious AI/ML projects, please feel free to contact us at:
- ionut.visan@transferrapid.com
- Ionuț Vișan's Linkedin
- Transfer Rapid's Linkedin
- Downloads last month
- 238
Inference Providers NEW
This model isn't deployed by any Inference Provider. 🙋 Ask for provider support
Model tree for TransferRapid/whisper-large-v3-turbo_ro
Base model
openai/whisper-large-v3 Finetuned
openai/whisper-large-v3-turbo