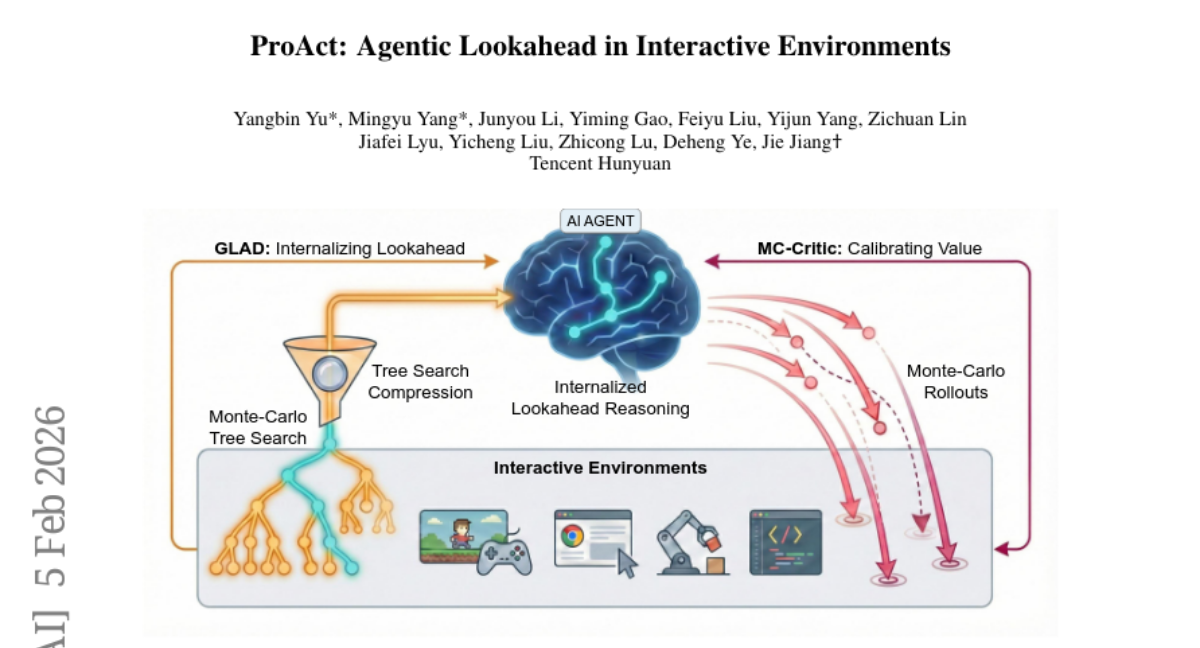
Submitted by johanneskirmayr 66 CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty BMW LLM Research Group 13 4
Submitted by yangzhi1 62 Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening AIFin Lab 10 4
Submitted by liufanfanlff 45 Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR · 6 authors 7 4
Submitted by XaiverZ 40 MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents Nanyang Technological University 20 3
Submitted by ShuoChen20 27 Context Forcing: Consistent Autoregressive Video Generation with Long Context TIGER-Lab 31 7
Submitted by yangxue 25 RISE-Video: Can Video Generators Decode Implicit World Rules? · 12 authors 20 3
Submitted by melisa 25 Accurate Failure Prediction in Agents Does Not Imply Effective Failure Prevention Writer 3
Submitted by PeterV09 19 Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations HKUST NLP Group 3
Submitted by Vilin97 17 Semantic Search over 9 Million Mathematical Theorems University of Washington Math AI Lab 4
Submitted by xusirui 16 InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions · 7 authors 3
Submitted by ShawnYing 16 Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities ByteDance Seed 1 5
Submitted by keyangx3 15 SocialVeil: Probing Social Intelligence of Language Agents under Communication Barriers · 6 authors 7
Submitted by Steven-Shaobo 15 Grounding and Enhancing Informativeness and Utility in Dataset Distillation Shanghai Jiao Tong University 4
Submitted by chengzu 13 Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning University of Cambridge 4
Submitted by shilinyan 10 SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs Accio 9 3
Submitted by Xiaoye08 10 LatentMem: Customizing Latent Memory for Multi-Agent Systems · 9 authors 16 3
Submitted by HughieHu 9 SAGE: Benchmarking and Improving Retrieval for Deep Research Agents · 5 authors 3
Submitted by changdae 9 Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents University of Wisconsin - Madison 3
Submitted by menik1126 7 V-Retrver: Evidence-Driven Agentic Reasoning for Universal Multimodal Retrieval · 9 authors 19 3
Submitted by clyu 5 Approximation of Log-Partition Function in Policy Mirror Descent Induces Implicit Regularization for LLM Post-Training Amazon 9 3
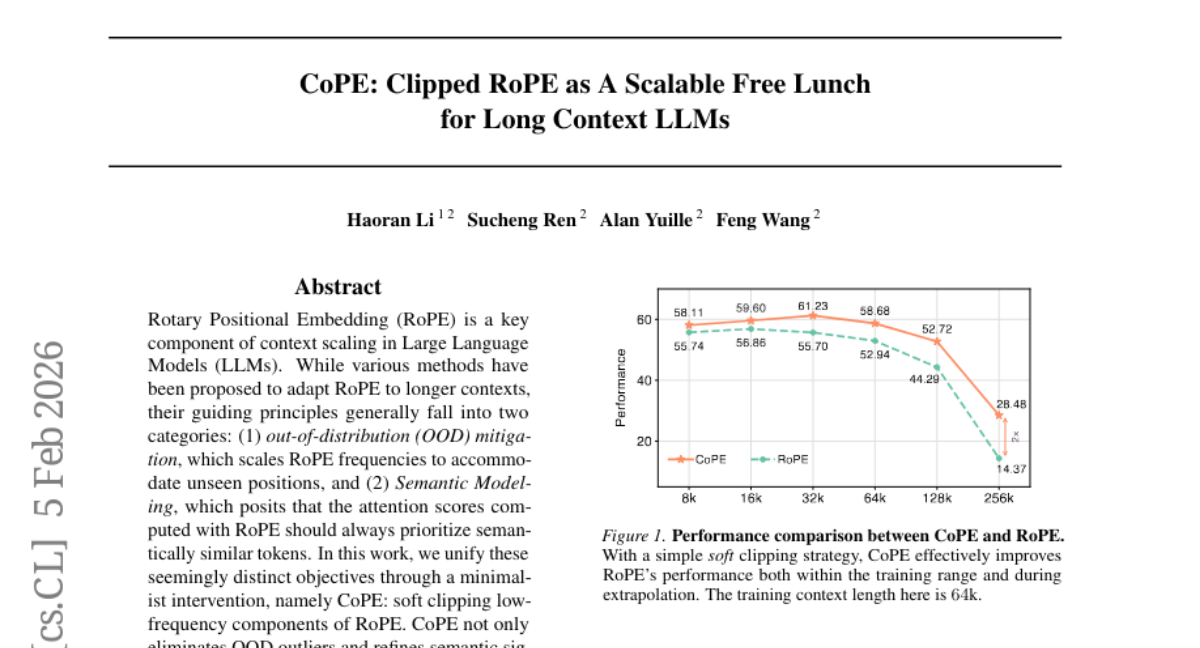
Submitted by haoranli-ml 4 CoPE: Clipped RoPE as A Scalable Free Lunch for Long Context LLMs Carnegie Mellon University 5 3
Submitted by Jimlkh 4 Breaking the Static Graph: Context-Aware Traversal for Robust Retrieval-Augmented Generation · 7 authors 3
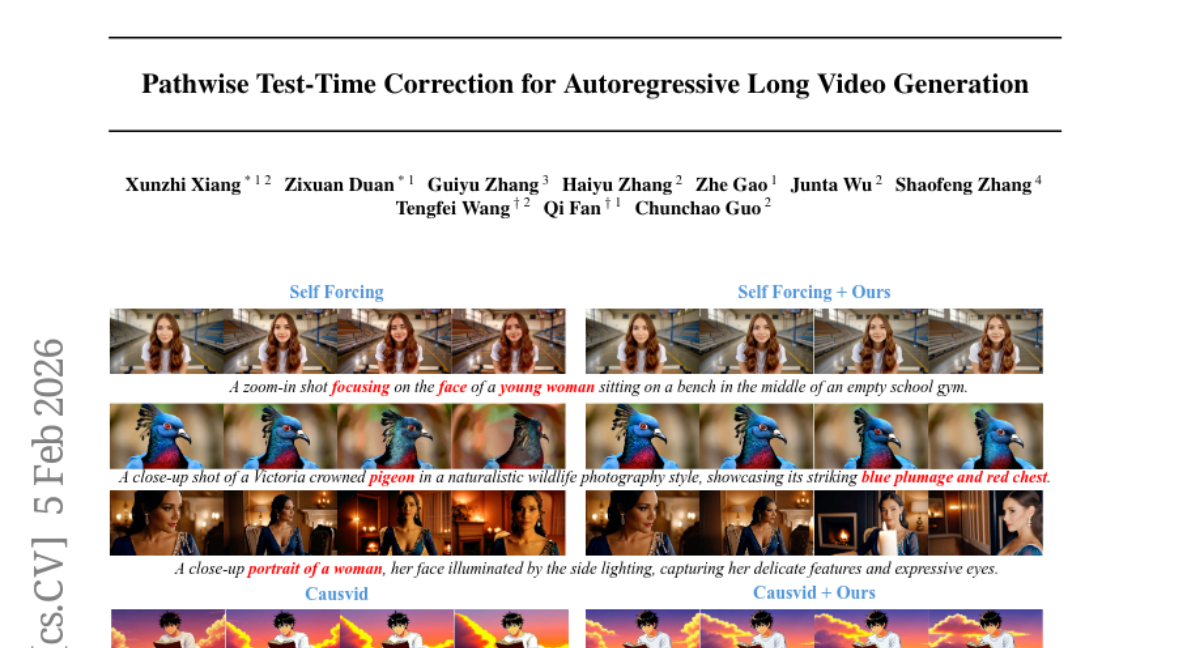
Submitted by taesiri 3 Pathwise Test-Time Correction for Autoregressive Long Video Generation · 10 authors 3
Submitted by taesiri 3 Late-to-Early Training: LET LLMs Learn Earlier, So Faster and Better ByteDance Seed 2
Submitted by wuruiqi0722 3 Infinite-World: Scaling Interactive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory MeiGen-AI 3
Submitted by ionutmodo 3 DASH: Faster Shampoo via Batched Block Preconditioning and Efficient Inverse-Root Solvers IST Austria Distributed Algorithms and Systems Lab 1 2
Submitted by qingyuanwu 2 A Unified Framework for Rethinking Policy Divergence Measures in GRPO · 9 authors 3
Submitted by RayY 2 Do Vision-Language Models Respect Contextual Integrity in Location Disclosure? Georgia Institute of Technology 3 3
Submitted by Speeeed 2 Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning · 4 authors 3
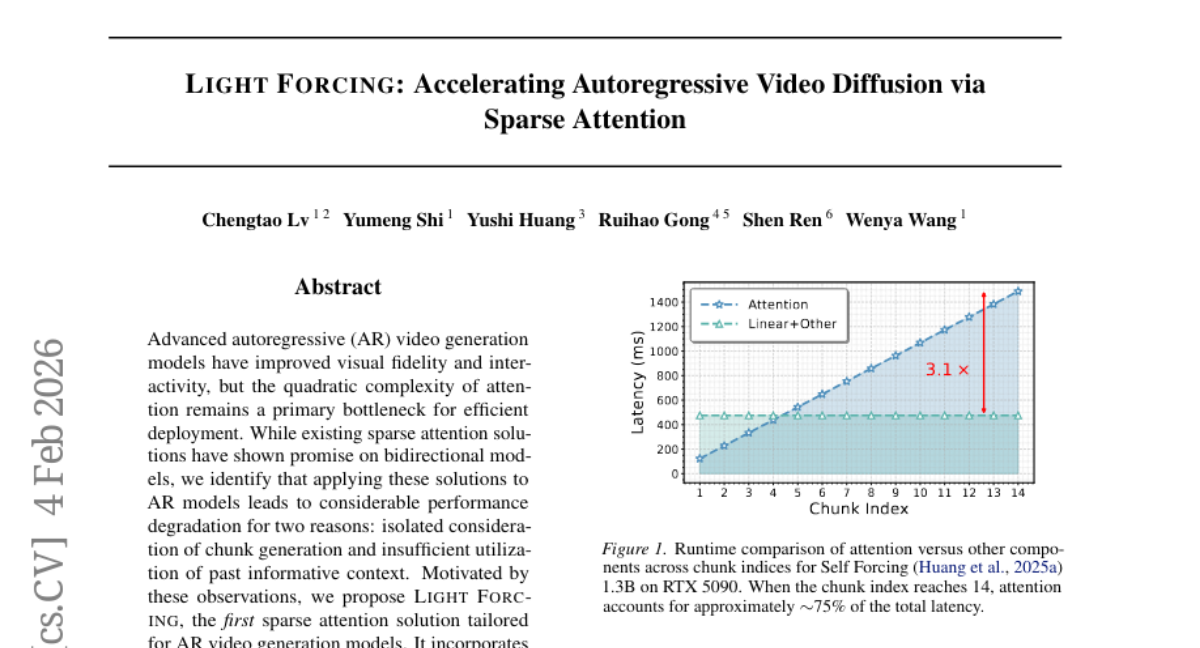
Submitted by Harahan 2 Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention · 6 authors 3
Submitted by Dongchao 1 UniAudio 2.0: A Unified Audio Language Model with Text-Aligned Factorized Audio Tokenization · 6 authors 91 3
Submitted by lucadellalib 1 Beyond Fixed Frames: Dynamic Character-Aligned Speech Tokenization Mila – Quebec Artificial Intelligence Institute 4
Submitted by Kavanavnlp - PhysicsAgentABM: Physics-Guided Generative Agent-Based Modeling Virginia Polytechnic Institute and State University 3
Submitted by Harahan - Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing · 7 authors 7 3
Submitted by abhishek9909 - Assessing Domain-Level Susceptibility to Emergent Misalignment from Narrow Finetuning · 6 authors 4


 johanneskirmayr
johanneskirmayr