Submitted by chengtan9907 178 The Trinity of Consistency as a Defining Principle for General World Models OpenDataLab 15 4
Submitted by jcy 142 From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models · 4 authors 28 3
Submitted by xiaochonglinghu 90 MobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios alibaba-inc 94 3
Submitted by Michael4933 33 Imagination Helps Visual Reasoning, But Not Yet in Latent Space Tsinghua University 11 3
Submitted by beanie00 26 Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization Microsoft 3
Submitted by SunbowLiu 24 AgentDropoutV2: Optimizing Information Flow in Multi-Agent Systems via Test-Time Rectify-or-Reject Pruning Harbin Institute of Technology 14 3
Submitted by Qianben 15 Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization OPPO 0 3
Submitted by sahalshajim 13 MediX-R1: Open Ended Medical Reinforcement Learning Mohamed Bin Zayed University of Artificial Intelligence 14 2
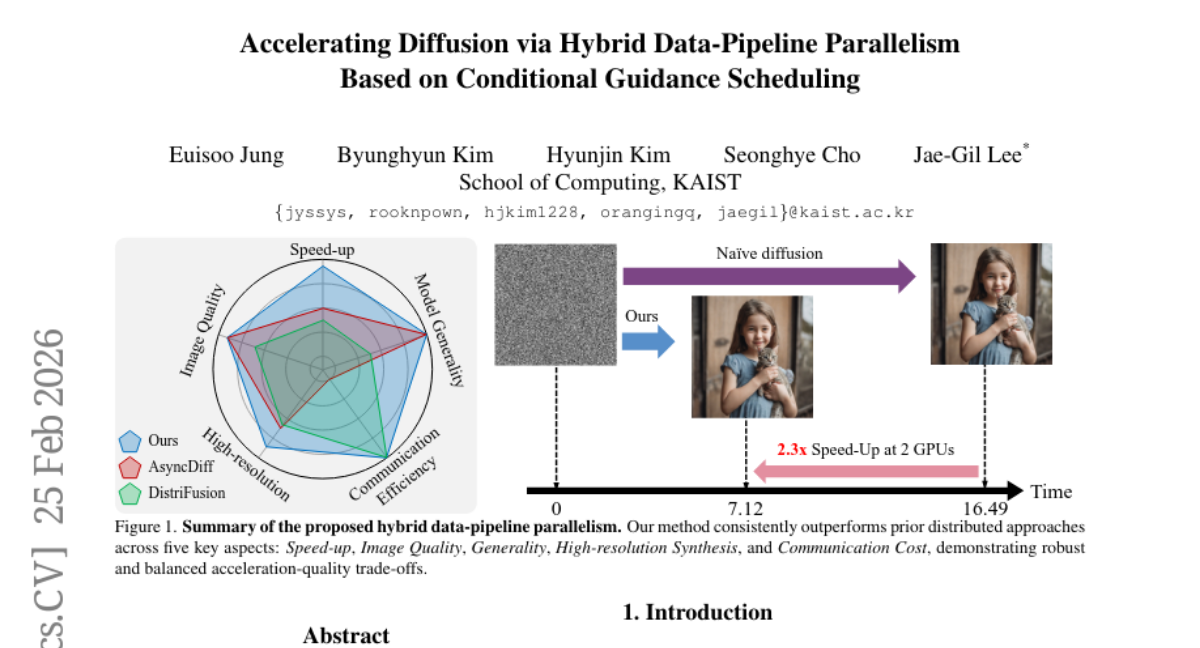
Submitted by Cabbalett 11 Accelerating Diffusion via Hybrid Data-Pipeline Parallelism Based on Conditional Guidance Scheduling · 5 authors 4 2
Submitted by WenjiaWang 9 EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents · 11 authors 45 2
Submitted by lcying 8 AI Gamestore: Scalable, Open-Ended Evaluation of Machine General Intelligence with Human Games Massachusetts Institute of Technology 3
Submitted by taesiri 5 Causal Motion Diffusion Models for Autoregressive Motion Generation · 3 authors 2
Submitted by billpsomas 4 Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation? Visual Recognition Group FEE CTU in Prague 2 2
Submitted by taesiri 2 Risk-Aware World Model Predictive Control for Generalizable End-to-End Autonomous Driving · 7 authors 1
Submitted by walterhernandez 2 DLT-Corpus: A Large-Scale Text Collection for the Distributed Ledger Technology Domain Exponential Science 0 2
Submitted by pb09204048 2 Overconfident Errors Need Stronger Correction: Asymmetric Confidence Penalties for Reinforcement Learning LinkedIn 2
Submitted by TahaKoleilat 2 MedCLIPSeg: Probabilistic Vision-Language Adaptation for Data-Efficient and Generalizable Medical Image Segmentation · 6 authors 3 2
Submitted by NicoleCho 2 No One Size Fits All: QueryBandits for Hallucination Mitigation · 5 authors 2
Submitted by NicoleCho 2 What Makes a Good Query? Measuring the Impact of Human-Confusing Linguistic Features on LLM Performance · 4 authors 2
Submitted by taesiri 1 DyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation · 10 authors 1
Submitted by zuazo 1 MEG-to-MEG Transfer Learning and Cross-Task Speech/Silence Detection with Limited Data HiTZ zentroa 4 2
Submitted by akhadangi - Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns · 1 authors 2
Submitted by cssen - Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models Sony 2


 chengtan9907
chengtan9907