Submitted by sliuau 113 GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization NVIDIA 82 6
Submitted by JingweiZuo 31 Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers Technology Innovation Institute 99 2
Submitted by yulunliu 30 RL-AWB: Deep Reinforcement Learning for Auto White Balance Correction in Low-Light Night-time Scenes · 4 authors 14 2
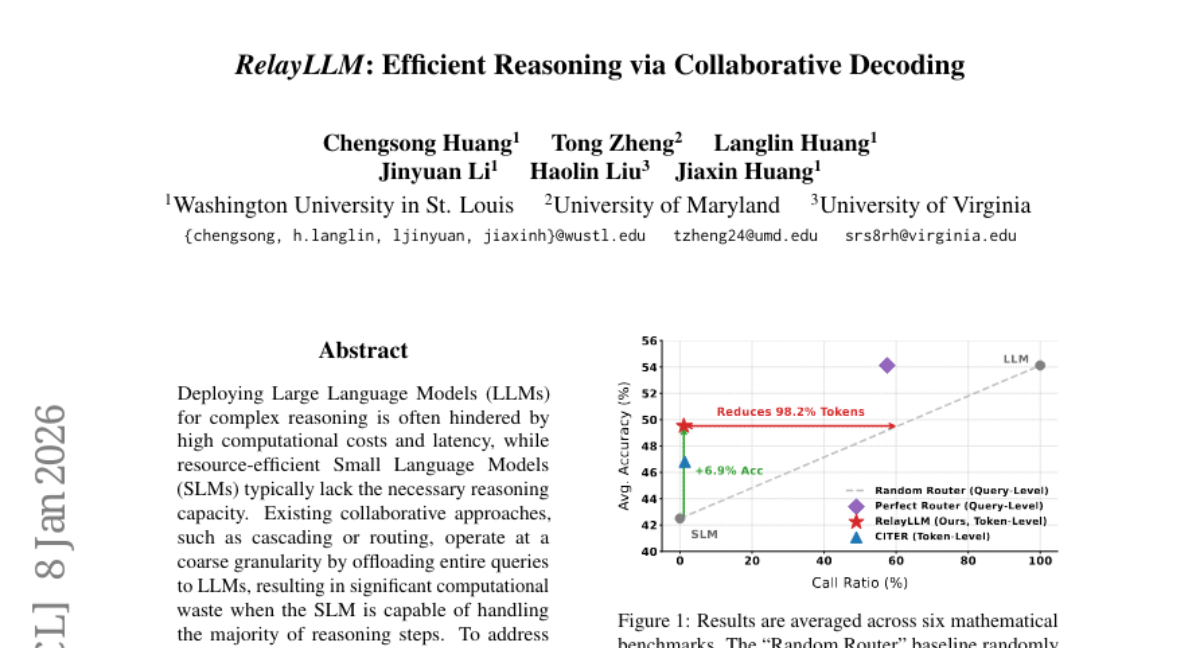
Submitted by ChengsongHuang 23 RelayLLM: Efficient Reasoning via Collaborative Decoding · 6 authors 9 2
Submitted by HikariDawn 21 RoboVIP: Multi-View Video Generation with Visual Identity Prompting Augments Robot Manipulation · 11 authors 11 3
Submitted by zzfoutofspace 21 AT^2PO: Agentic Turn-based Policy Optimization via Tree Search Tencent 4 2
Submitted by ANUHW 17 Few Tokens Matter: Entropy Guided Attacks on Vision-Language Models Australian National University 2
Submitted by taesiri 16 VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice AI at Meta 11 1
Submitted by taesiri 11 VerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control · 6 authors 2
Submitted by YanAdjeNole 11 The Illusion of Specialization: Unveiling the Domain-Invariant "Standing Committee" in Mixture-of-Experts Models The Fin AI 2
Submitted by danielhzlin 6 DiffCoT: Diffusion-styled Chain-of-Thought Reasoning in LLMs HKBU NLP Lab 2
Submitted by refkxh 4 Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing · 14 authors 1 3
Submitted by callanwu 3 DocDancer: Towards Agentic Document-Grounded Information Seeking Peking University 2
Submitted by billli 3 One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling · 9 authors 2
Submitted by habibian 2 PyramidalWan: On Making Pretrained Video Model Pyramidal for Efficient Inference Qualcomm 2
Submitted by remiii25 2 ProFuse: Efficient Cross-View Context Fusion for Open-Vocabulary 3D Gaussian Splatting National Yang Ming Chiao Tung University 0 2
Submitted by habibian 2 ReHyAt: Recurrent Hybrid Attention for Video Diffusion Transformers Qualcomm 5
Submitted by XiangZ 2 Guardians of the Hair: Rescuing Soft Boundaries in Depth, Stereo, and Novel Views ETH Zurich 2
Submitted by pudashi 2 Memorization in 3D Shape Generation: An Empirical Study Princeton University 2
Submitted by di-zhang-fdu 1 AgentDevel: Reframing Self-Evolving LLM Agents as Release Engineering · 1 authors 2
Submitted by guaguaa 1 Scaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing Elefant AI 24 2
Submitted by mengcy 1 Beyond Binary Preference: Aligning Diffusion Models to Fine-grained Criteria by Decoupling Attributes Zhejiang University 1
Submitted by mbar0075 1 Enhancing Object Detection with Privileged Information: A Model-Agnostic Teacher-Student Approach · 7 authors 3 2
Submitted by Approximetal 1 LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models LEMAS 2
Submitted by water-fountain 1 Towards Open-Vocabulary Industrial Defect Understanding with a Large-Scale Multimodal Dataset · 3 authors 1 3
Submitted by de-Rodrigo - VERSE: Visual Embedding Reduction and Space Exploration. Clustering-Guided Insights for Training Data Enhancement in Visually-Rich Document Understanding CICLAB Comillas ICAI 1 2
Submitted by shuhaibmehri - Learning User Preferences Through Interaction for Long-Term Collaboration · 4 authors 2
Submitted by ttttonyhe - Safety at One Shot: Patching Fine-Tuned LLMs with A Single Instance · 7 authors 2


 sliuau
sliuau