Submitted by BishopGorov 61 Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling Tencent 17 3
Submitted by ScottQu 31 Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space ByteDance Seed 4
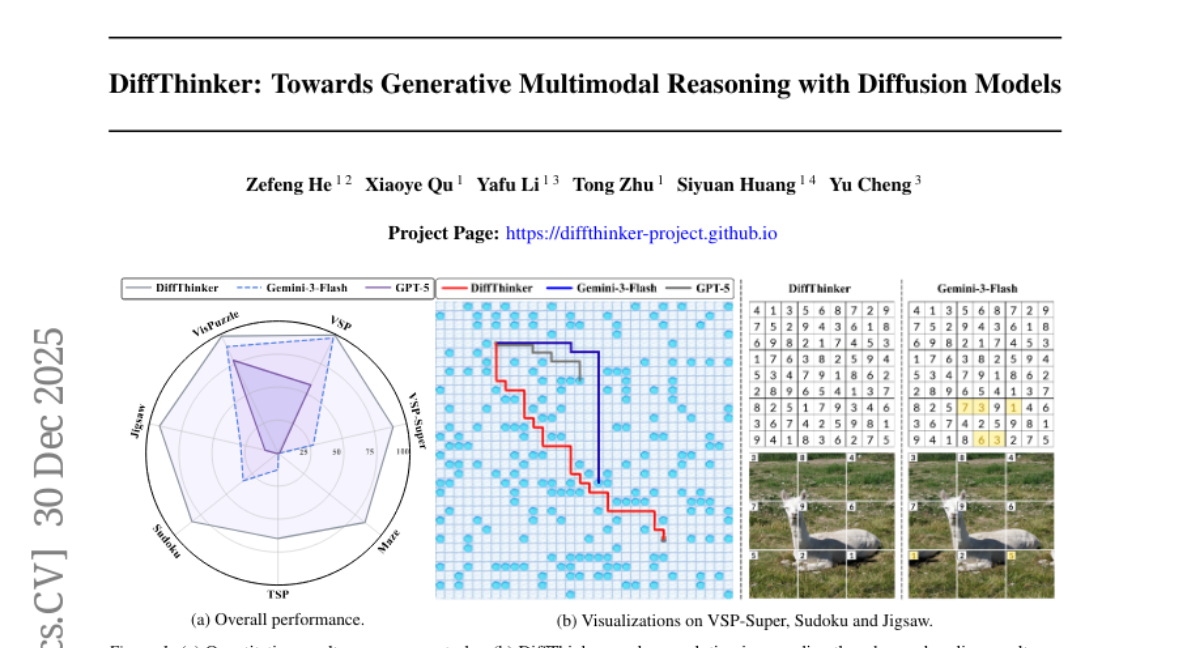
Submitted by Spico 20 DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models · 6 authors 21 4
Submitted by akhaliq 3 Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow · 5 authors 3
Submitted by akhaliq 2 FlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation · 4 authors 3
Submitted by bulentsoykan 1 TESO Tabu Enhanced Simulation Optimization for Noisy Black Box Problems · 3 authors 3 2


 BishopGorov
BishopGorov